Home /
Expert Answers /
Computer Science /
given-a-list-of-sentences-maintained-by-a-python-variable-named-corpus-corpus-1-1ike-business-pa693
(Solved): Given a list of sentences maintained by a Python variable named corpus . corpus = [ 1 1ike business ...
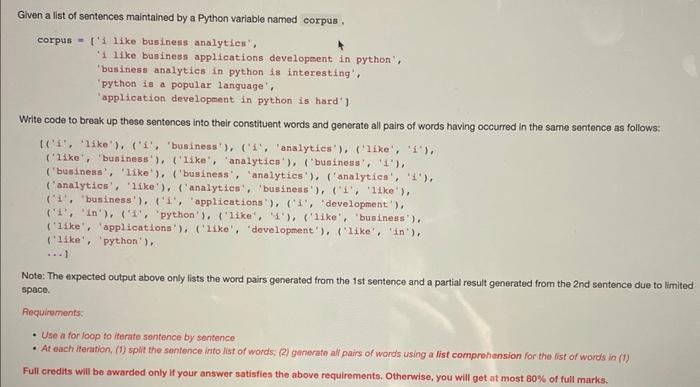
Given a list of sentences maintained by a Python variable named corpus . corpus = [ 1 1ike business analytics' , "I like buginesn applications development in python", 'business analytics in python is interesting', 'python is a popular lanquage', "application development in python is hard'] Write code to break up these sentences into their constituent words and generate all pairs of words having occurred in the same sentence as follows: (('i', "1ike'), ("i', 'business'), (" 1 ', 'analytics'), ('like', 'i'), ('like', 'business'), ('like', 'analytics'), ('business', '1'), ('business', "Iike'), ('business', 'analytics'), ('analytica', 'i'), ('analytios', 'Iike'), ('analyties', 'business'), ("i', '1ike'), ("1', "business'), ('I', "applications"), ('i', "dovelopment'), ('i', "in'), ("1", "python'), ('like', 'i'), ('like', "business'), ('like', applications'), ('Like', "dovelopnent'), ('like', 'in'), ('1ike', 'python'), Note: The expected output above only lists the word pairs generated from the 1st sentence and a partial result generated from the 2 nd sentence due to limited space. Alequirements. - Use a for loop to iterate sentence by sentence - At each iteration, (1) split the santence into list of words; (2) generate all pairs of words using a list comprohension for the bist of words in (1) Full credits will be awarded only if your answor satisfies the above requirements. Otherwise, you will get at most of full marks.
Expert Answer
Here is the python code for the given question:pairs.pycorpus = ['i like business analytics', 'i like business applications developmen